
Dedicated AI Model Serving
While Theta EdgeCloud provides on-demand AI model APIs for serverless development, there are times where the developers might want dedicated model deployments to optimize performance and latency. For this we provide a variety of model templates from image/video generation to large language models, including the most popular open-source GenAI models including Llama 3, Stable Diffusion, ControlNet, Whisper, and more. This documentation provides a guide on how to deploy and interact with your dedicated models using web interfaces and APIs.
Deploying a Model
You can find all available model templates on the "Dedicated Model Launchpad" page, which can be assessed by simply first clicking on the "AI" icon on the left bar, and then navigate to the "Dedicated models" page.
.png")
Clicking on a model template should open a popup window where you can configure the deployment settings. Once you have set up the configurations, click on the Create New Deployment button to deploy the model. Note that you may need to provide container environment variables for some of the deployments. In particular, LLM deployments such as Gemma 2B, Llama 2 7B, Llama 3.1 70B, and Llama 3 8B require the HuggingFace key (a.k.a. security token) of your HuggingFace account. You can find more information on how to obtain the HuggingFace key here. Also, you can use GPUs from community nodes by toggling on Community Nodes.
.png")
After the deployment process is completed, you can find the new deployment listed on the Dedicated Deployments page.
.png")
Interacting with Models
The currently available standard model templates can be grouped into two categories: Large Language Models (LLMs) and media generation/transformation models.
Large Language Models (LLMs)
- Gemma 2B LLM
- Mistral 7B LLM
- Code Llama 7B LLM
- Llama 2 7B LLM
- Llama 3 8B LLM
- Llama 3.1 70B LLM
LLMs are accessible through OpenAI-compatible APIs.
Using the LLM API
The LLMs can be accessed using the standard OpenAI API format. The code samples can be found by clicking the Inference Endpoint of an LLM model deployment.
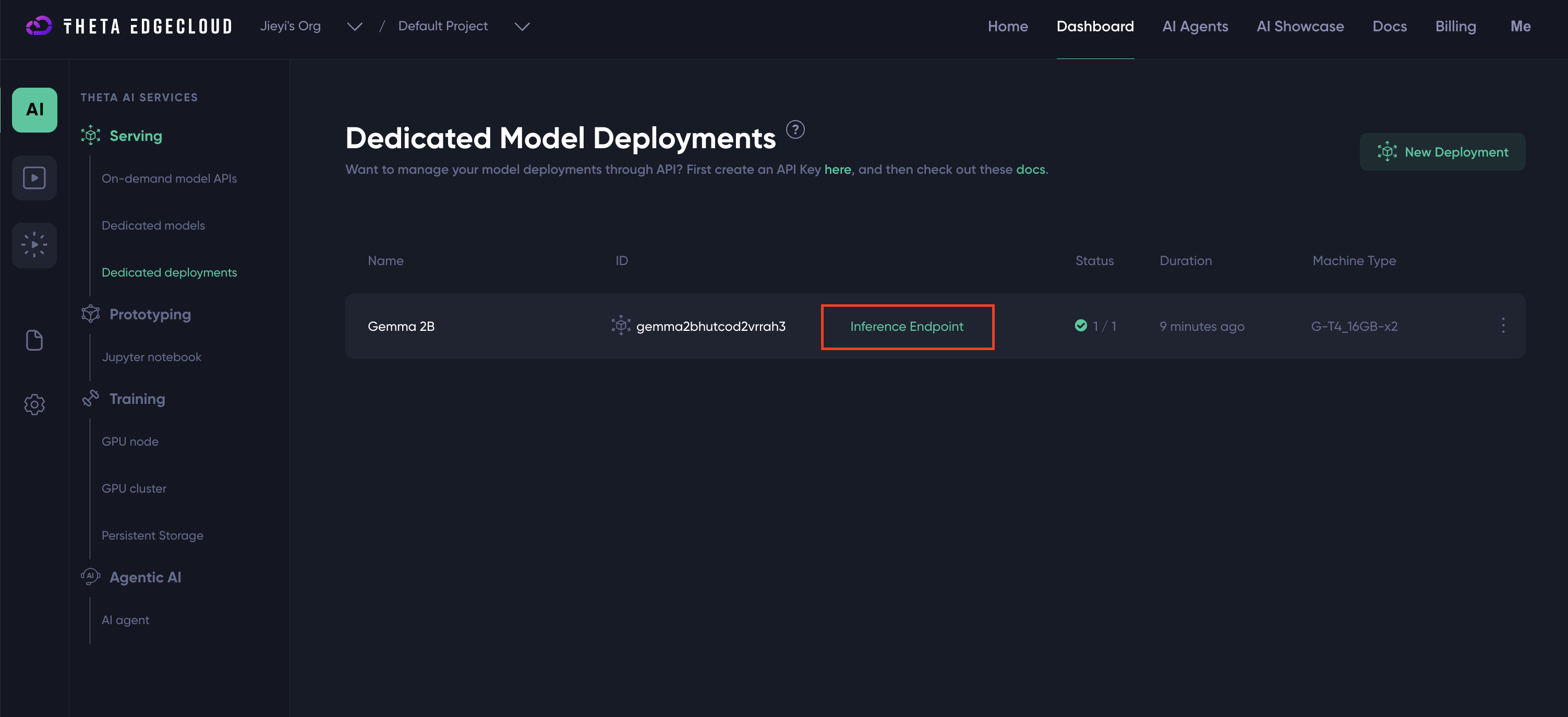
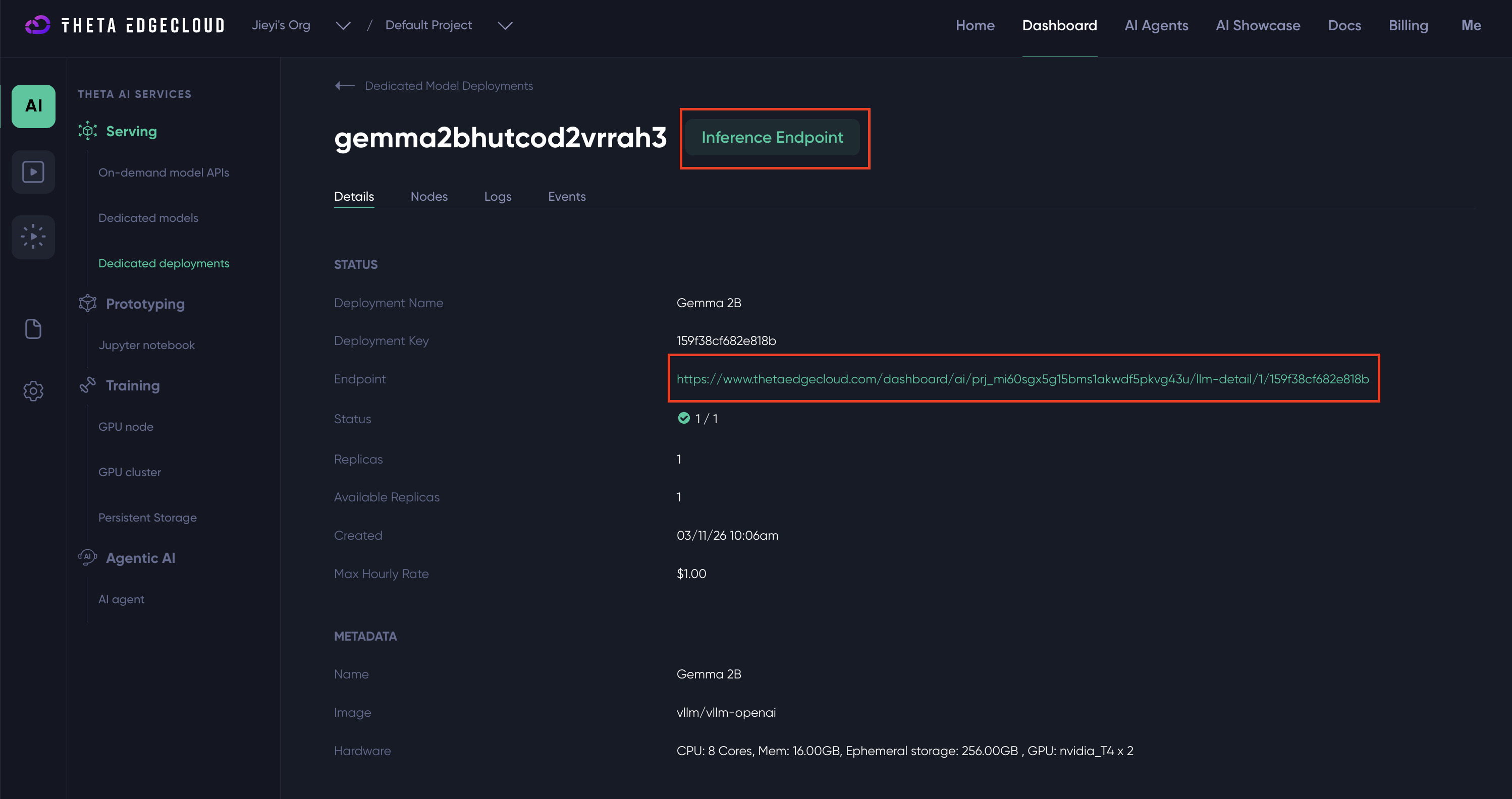
The "Inference Endpoint" button should link to a page similar to the one below with code samples for interacting with the LLM model.
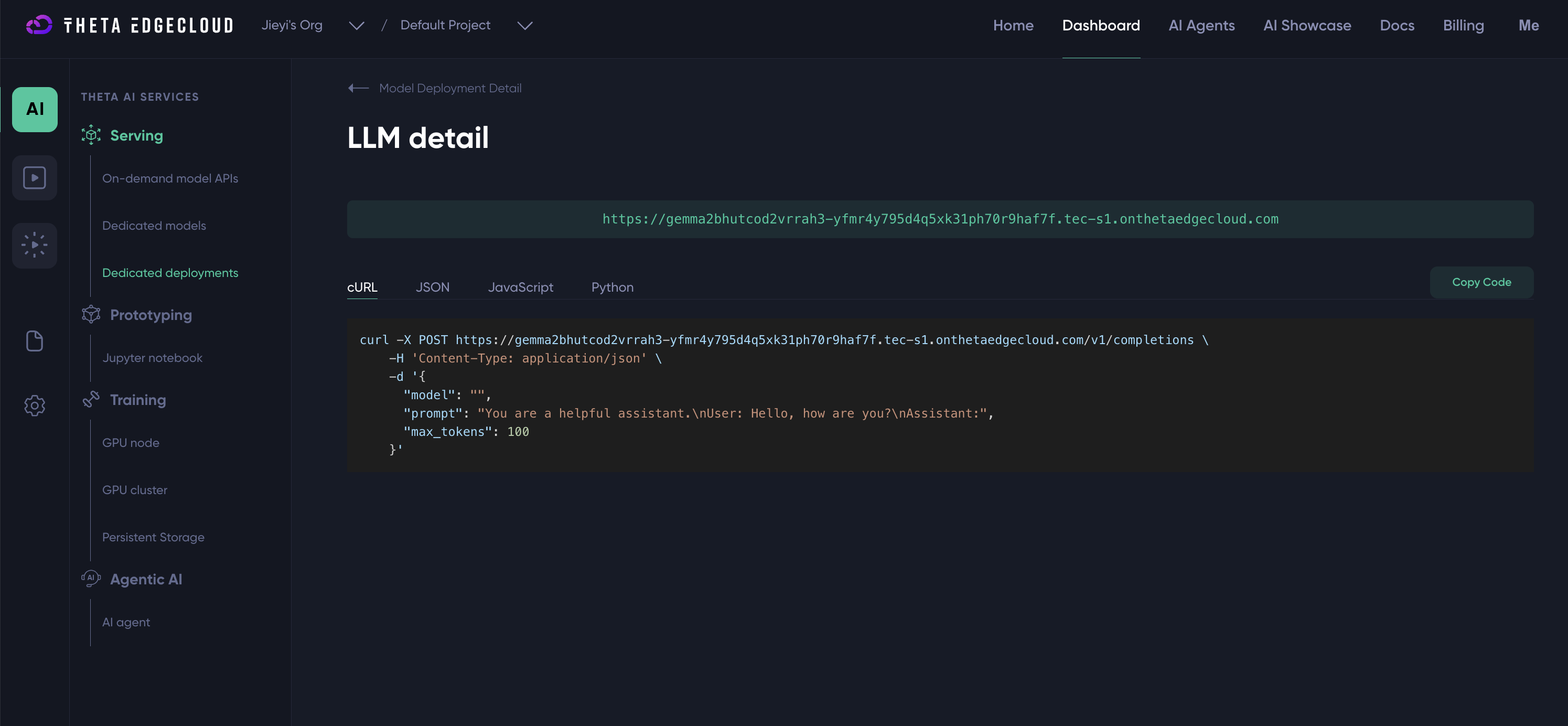
Interacting with LLM Models via APIs
Below is a quick guide to interacting with these deployments directly via APIs:
1. Model Listing
To list available models, use the following cURL command:
curl {MODEL_ENDPOINT}/v1/modelsThis will return information about available models, including model ID which is used for making API requests.
{
"object": "list",
"data": [
{
"id": "meta-llama/Llama-2-7b-chat-hf",
"object": "model",
"created": 1712945959,
"owned_by": "vllm",
"root": "meta-llama/Llama-2-7b-chat-hf",
"parent": null,
"permission": [
{
"id": "modelperm-eccb343d05ab41459c90403d74feb16e",
"object": "model_permission",
"created": 1712945959,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}2. Sending Requests
To send a request to the LLM, use the model ID obtained from the listing:
curl -X POST {MODEL_ENDPOINT}/v1/chat/completions -H 'Content-Type: application/json' -d '{"model": "model-id", "messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello, how are you?"}], "max_tokens": 100}'This will initiate a conversation with the model, which will respond based on the input provided.
{
"id": "cmpl-abe715dfff9e48278c95e6f6d3025aeb",
"object": "chat.completion",
"created": 1712946059,
"model": "meta-llama/Llama-2-7b-chat-hf",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": " Hello! *adjusts glasses* I'm up and running, thank you for asking! I'm here to help with any questions or tasks you may have, so feel free to ask me anything. How can I assist you today?"
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"usage": {
"prompt_tokens": 34,
"total_tokens": 87,
"completion_tokens": 53
}
}It is recommended to use Python or JavaScript clients for API interactions. These clients can be installed by:
- Python:
pip install openai - JavaScript:
npm install openai@^4.0.0
For additional details on API usage, including parameters and configurations, please visit:
Community libraries in other programming languages are also supported. More information can be found here:
Media Generation/Transformation Models
- Stable Diffusion: Generates images from text descriptions.
- Stable Diffusion with ControlNet: Offers controlled generation of images from text.
- Stable Video Diffusion: Generates video from image.
- Whisper: Transforms audio into text.
In addition, the latest models such as z-image, Flux and LLaVA are also available. These models are accessible via Gradio, which provides both a user-friendly web UI and an API endpoint.
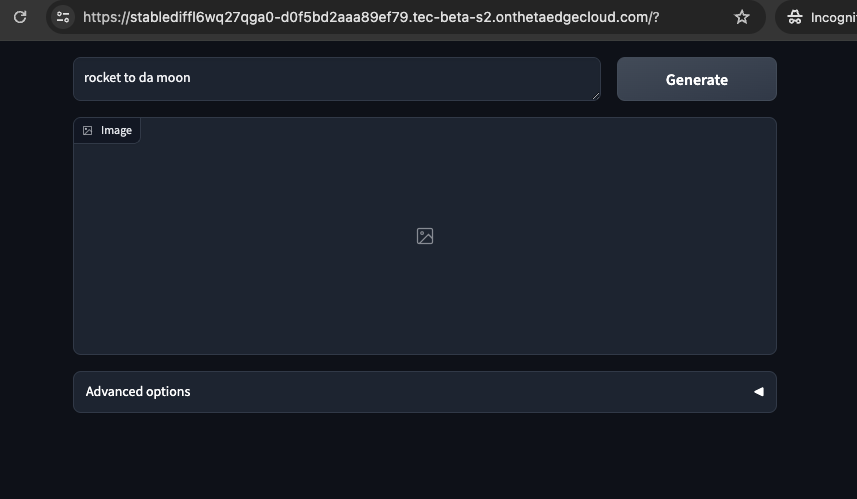
Web UI
To interact with any model through the web interface, simply navigate to the deployed model's Inference endpoint URL in your browser. The Inference endpoints of each of the model deployments can be found on the Model Deployment page.
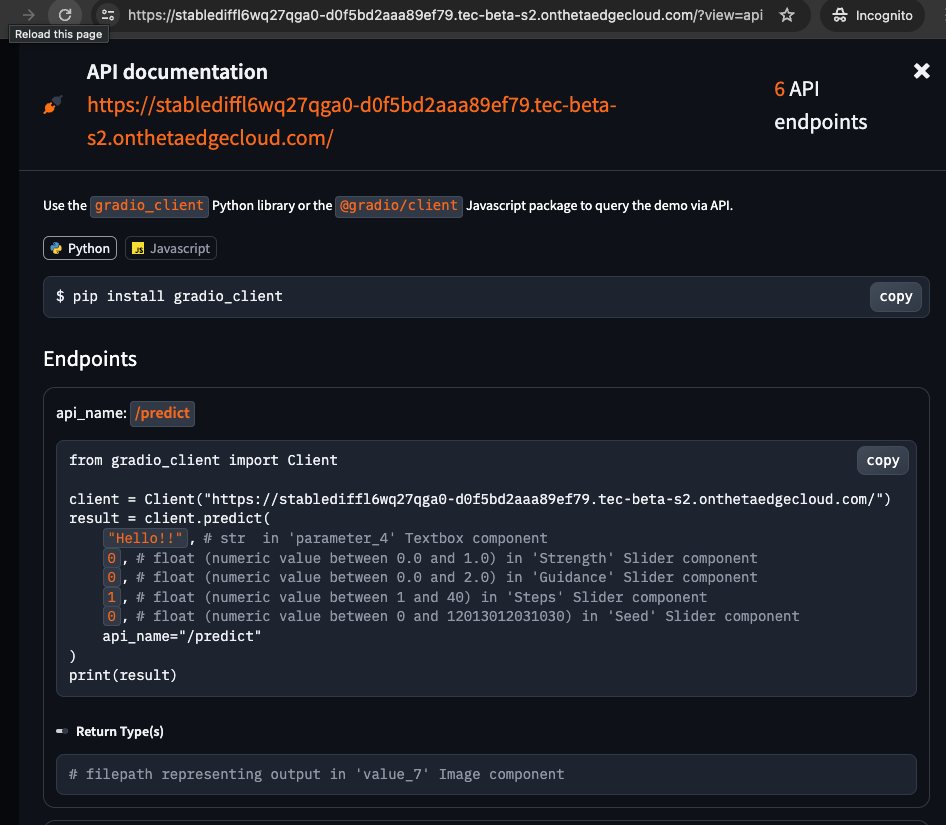
API Access
API access is provided for all models. Detailed API documentation is available at {INFERENCE_ENDPOINT}?view=api (just append the inference endpoint with ?view=api, for example,https://xxx-xx.tec-s1.tec-s1.onthetaedgecloud.com/?view=api). It is recommended to use Python or JavaScript clients for API interactions.
Updated 4 months ago